

Running dbt with Airflow
Running dbt with Airflow
Several ways to run dbt pipelines with Apache Airflow


Apache Airflow is a very popular orchestration tool in the data engineering world. One question that often arises in many teams is: "Is it possible to run dbt pipelines with Airflow?" Of course it is, and I'm going to show you how to implement this in practice.
Since Airflow is an open-source tool, there's no single "correct" way of integrating the two tools. Different teams may integrate them differently and even create their own integrations to serve specific requirements.
In this post, I'll show you two ways (+ one bonus way) of integrating them together. One way is simple and straightforward. The other is more custom and requires an additional package to be installed in your Airflow environment. Let's get started!
All code for his post you can find in this repository!
Option 1: Naive approach
The naive approach is straightforward and doesn't require external packages to be installed. However, since dbt itself is a Python package, you'll need to add it to your Airflow dependencies.
Once that's done, you can simply create a DAG that uses BashOperator to trigger dbt commands. Here's a sample code that runs three dbt commands: seed, run, and test:
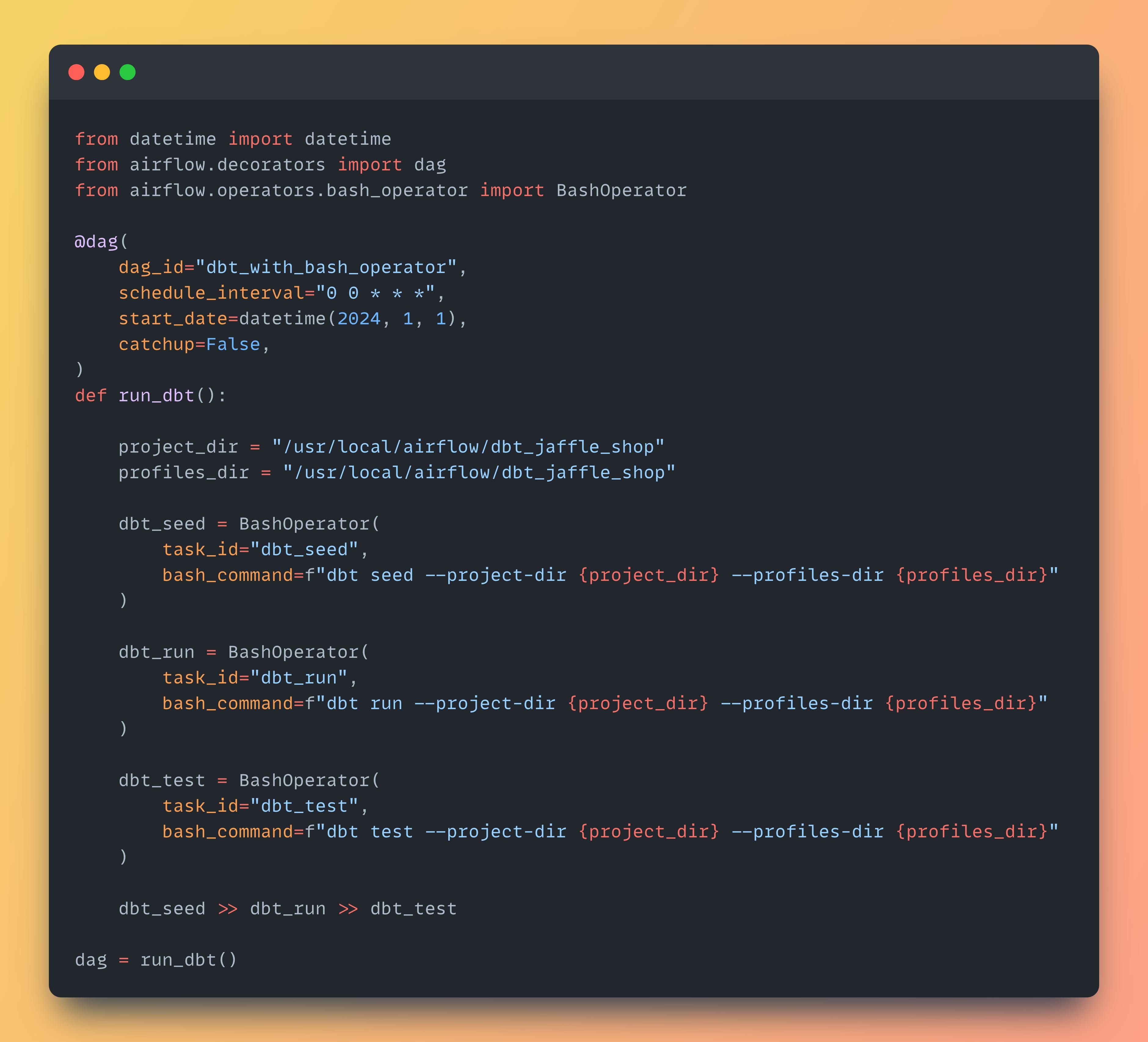
There are a few important points to pay attention to.
First, ensure you specify the correct paths to your dbt project folder and the folder containing dbt profiles. Since there's no standard location for a dbt project, it could be in any subfolder of your Airflow repository. By using the flags --project-dir and --profiles-dir, we ensure that the dbt CLI uses the correct path to the project.
Second, as you've likely figured out from the previous point, you'll need to commit profiles.yml to the repository. Don't worry — there's no need to store your credentials there. You can simply read environment variables to make it work.
With such simple setup you get a simple way to run dbt models from Airflow:
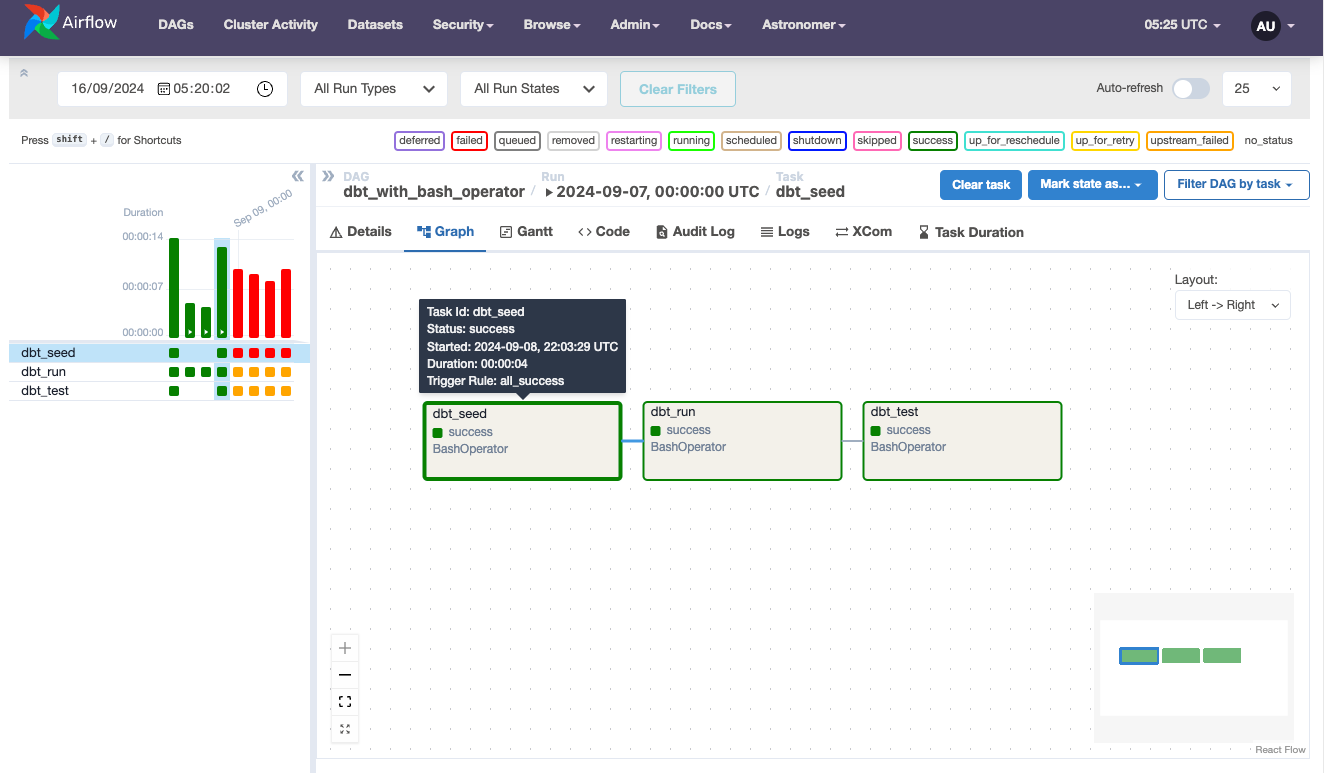
However, there are several fundamental flaws with this option.
The main drawback is the monolithic architecture of the pipeline. You can't see the same DAG of models in Airflow as you do in dbt documentation. This means that if one model or test fails, you have to re-run the entire pipeline, as there's no way to pick up from the failure point.
Additionally, installing dbt alongside Airflow's main dependencies may lead to conflicts.
The need to commit profiles.yml to the repository also adds complexity. Wouldn't it be great to simply reuse connections from Airflow to run the dbt pipeline?
That's why the folks at Astronomer implemented a package called astronomer-cosmos that can tackle these limitations.
Option 2: Astronomer-cosmos package
The Astronomer-cosmos package for Apache Airflow enables you to run dbt Core projects as Airflow DAGs and Task Groups.
According to its developers, this approach offers several benefits:
Run dbt projects against Airflow connections instead of dbt profiles
Ability to install dbt in a separate virtual environment to avoid dependency conflicts with Airflow
Simulate dbt build command by running tests immediately after a model is done to catch issues early
Use Airflow’s sensors to immediately run models after upstream ingestion
Turn each dbt model into a task/task group and configure retries, alerting, etc.
Here is a very simple code that can get you started:
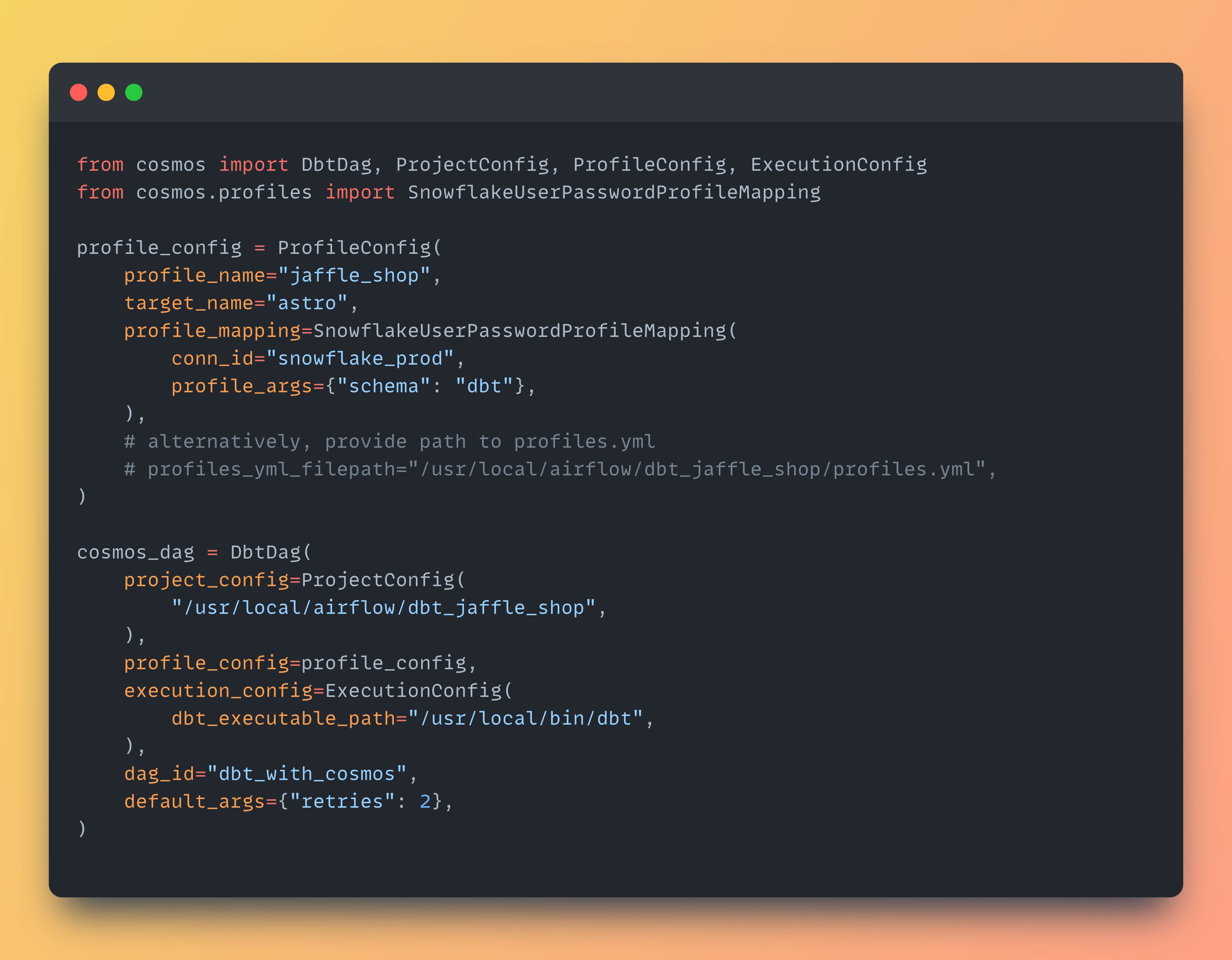
As you can see, you'll need to provide a few configuration options.
Similar to the previous example, configure a full path to the dbt project. Additionally, in the execution_config, you should add a path to the dbt executable (in case it's in a separate virtual environment).
The profile_config variable contains settings for dbt profiles. Here, you can either use a path to profiles.yml (similar to the previous example) or use a connection from Airflow, in this case to Snowflake.
The DbtDag is a wrapper class that splits each model into a separate task, like so:
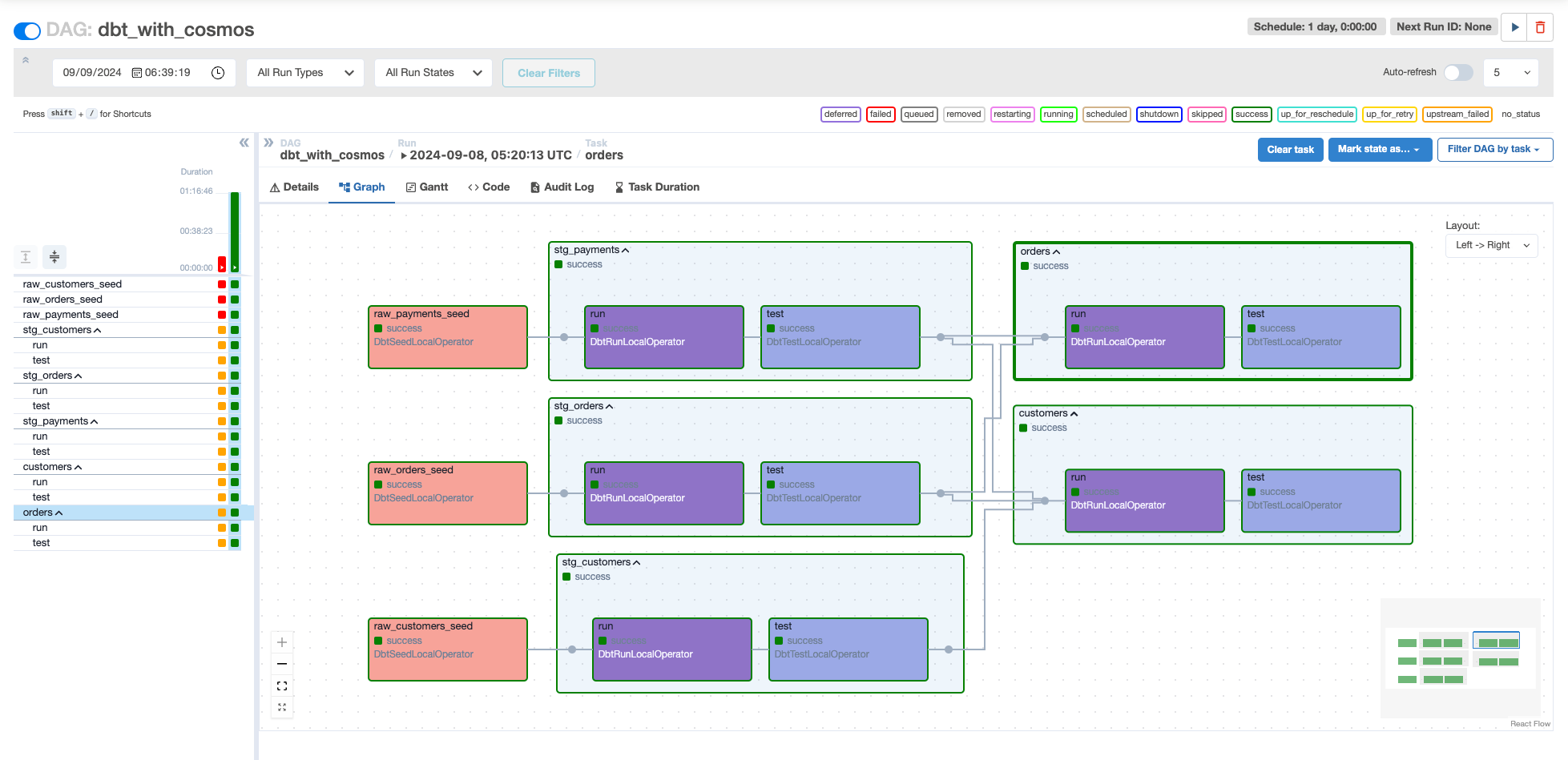
As you can see in the screenshot, each model task is followed by another task with tests for that model. This approach provides behavior similar to the dbt build command.
You can configure the DAG in many ways.
Using the DbtTaskGroup class, you can integrate dbt as a step within a more complex DAG. The render_config option allows you to make node selections for models, seeds, tags, and more. You can find all these examples in the demo repository: https://github.com/astronomer/cosmos-demo/tree/main
Bonus: using Airflow with dbt Cloud
If you're using dbt Cloud and want to leverage Airflow's scheduling capabilities, you can do so with the help of an official package. This package enables you to submit dbt jobs, check job results, and download artifacts. By combining Airflow with dbt Cloud, you can create a highly customized data pipeline tailored to your specific use case.
The package can be installed as:
pip install apache-airflow-providers-dbt-cloud[http]To connect to dbt Cloud, you need to generate a service token. This token, along with your account ID and URL (found in Settings → Account), can be stored in Airflow’s connections. Alternatively, provide credentials as an environment variable:
export AIRFLOW_CONN_DBT_CLOUD_DEFAULT='dbt-cloud://account_id:secret_token@my-urlgetdbt.com'Here is a simple DAG that can trigger dbt job from dbt Cloud:
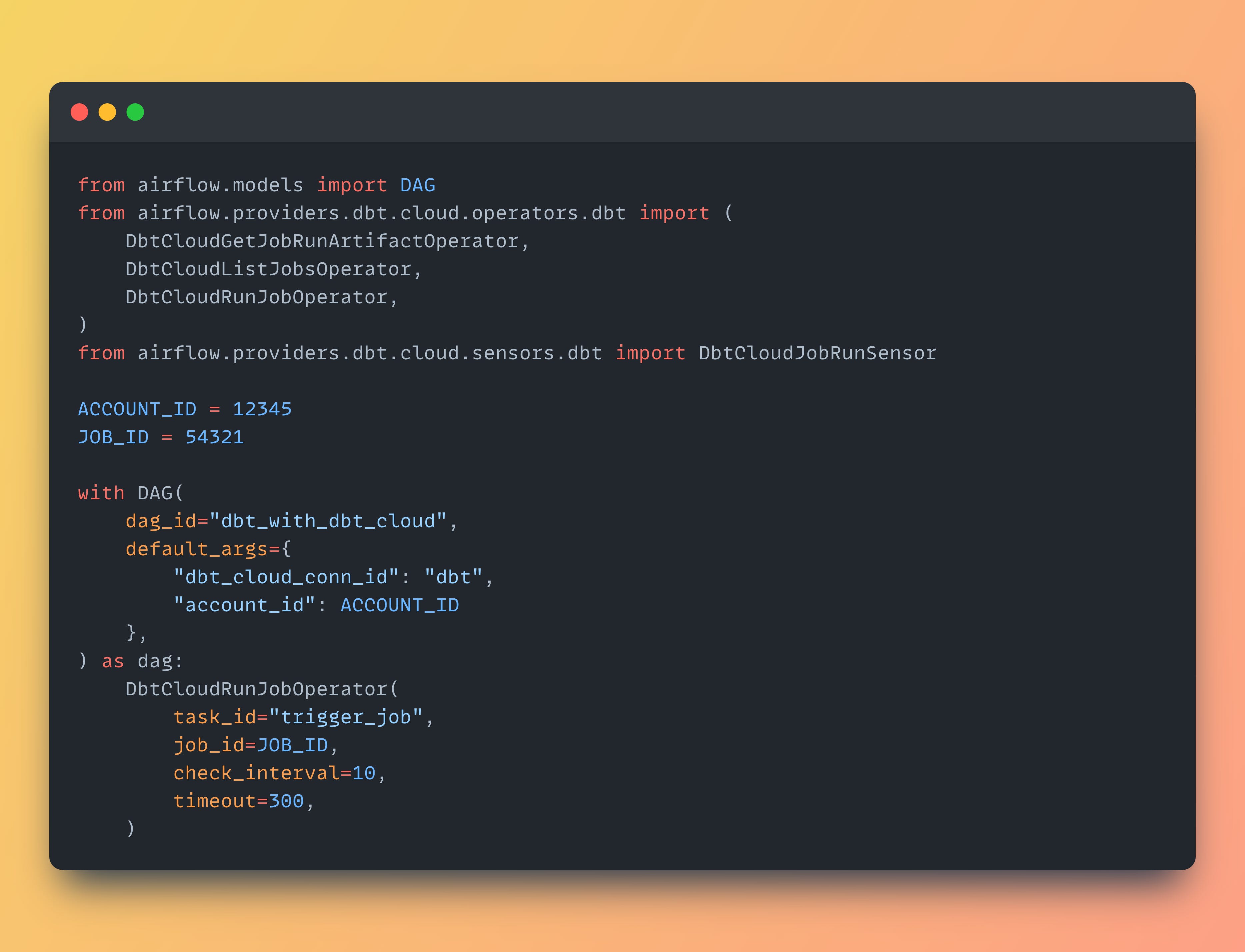
This DAG simply triggers a dbt job configured in dbt Cloud environment. It also is possible to make this task DbtCloudRunJobOperator asyncronous by providing wait_for_termination=False argument.
If you liked this issue please subscribe and share it with your colleagues, this greatly helps me developing this newsletter!
See you next time 👋
what if you have more than 400 DBT models? is the DBTDag still the best option?
Is better to have 400 tasks instead of just 3?
Nice article. What about running in k8s using docker and pod operator?