


How to Get the Most Out of dbt's Built-In Tests
Build superior tests using only built-in features


Out of the box, dbt Core provides several types of data tests that can be applied to your models. Data tests offer a simple way to check whether your data is complying with your expectations.
Built-in tests are a great opportunity to start testing your models. However, many analytics engineers are not aware that even default tests offer great flexibility and additional features that allow for very customized setups for each project.
Today, I want to share a couple of tips that could make dbt's built-in tests more powerful and useful.
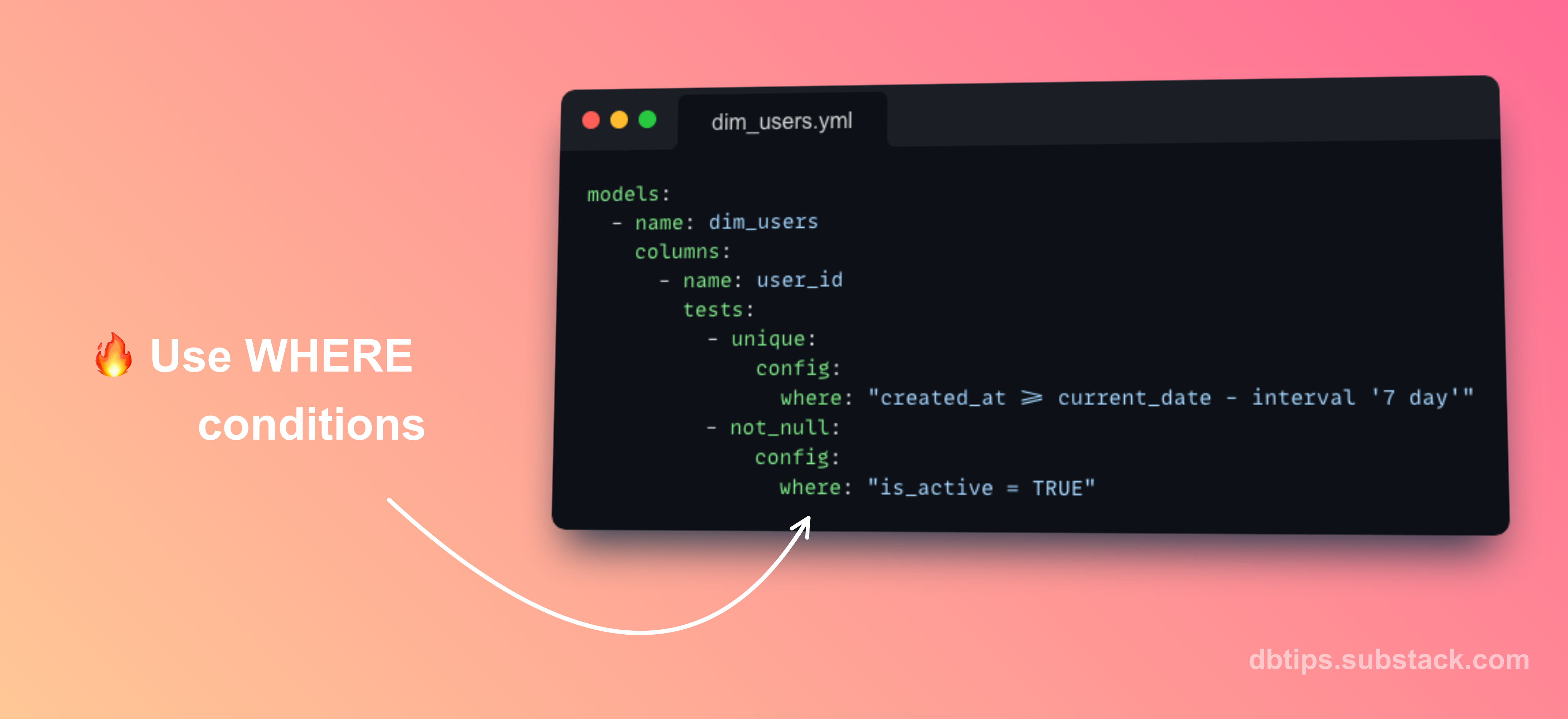
Tip 1: Use WHERE conditions in generic tests
When dbt tests your model, it scans the entire table for errors. In some cases, this may be necessary, such as when the table is small or when strict testing policies are required.
However, in many cases, it is unnecessary and you may want to test only specific rows or the most recent data. Additionally, performing a full scan of the table every day can result in high costs, so it may be beneficial to save some compute power and run time.
It is possible to add WHERE clause to generic by using a config block and where property:
models:
- name: dim_users
columns:
- name: user_id
tests:
- not_null:
config:
where: "created_at >= current_date - interval '7 day'"The WHERE clause will be added to the testing SQL and executed.
Tip 2: Adjust test severity and warning conditions

Another thing you can do is to add test severity. Some test failures may be hard errors, but others are just warnings. Warnings are unpleasant, but they can be safely skipped during pipeline execution, because they are not disrupting your models.
And here is another case. Imagine you have a table with millions of rows, and suppose one row contains an error. In this case, it would be better to mark the error as a warning, since its impact is minimal.
dbt allows you set a test severity as “warning” or set a threshold when the test is considered as error:
tests:
- not_null:
config:
severity: warn
warn_if: ">0"
error_if: ">100"In the example above, if a column has 1 or more missing values, dbt will consider it a warning. If the number of failures is greater than 100, then the test will throw an error.
Tip 3: Custom generic tests

Default dbt project only provides you with 4 generic tests:
not_null
unique
accepted_values
relationship
You can easily create your own custom generic tests. Custom generic tests should be stored in the /tests/generic folder, or in the /macros folder (although I prefer the former). The test should be a SELECT statement that returns failed records, wrapped in the test macro.
For example, let’s create a test that checks that a column contains only positive numbers:
{% test is_positive(model, column_name) %}
select *
from {{ model }}
where {{ column_name }} < 0
{% endtest %}For generic tests, the first argument should always be called "model", as this identifies a resource from the project (e.g. model, data source, seed). The second argument may be optional (we will discuss why in the next tip).
Also, you can easily add more parameters and use them in the query:
{% test is_within_range(model, column_name, from, to) %}
select *
from {{ model }}
where {{ column_name }} not between {{ from }} and {{ to }}
{% endtest %}You can call such tests similarly to default generic tests:
models:
- name: orders
columns:
- name: price
tests:
- is_positive
- is_within_range:
from: 29
to: 99Before implementing a custom generic test, it makes sense to check external packages like dbt_utils or dbt_expectations. There is a high chance that a similar test has already been implemented in one of these packages.
Tip 4: Use generic tests on a model

In some cases, you may need to access several columns in the same test. One approach is to implement a singular test that will be specific to a particular model. However, another option is to use generic tests in a more intelligent way.
Let’s imagine an example where you want to test uniqueness of two columns. You could implement such test like this:
models:
- name: orders
tests:
- unique:
column_name: "(order_id || '-' || user_id)"Here I moved unique test from column definition to the root of the model. Then, I used column_name parameter directly to provide concatenated columns of order_id and user_id.
Do you remember when I mentioned in a previous tip that the column_name parameter can be optional in generic tests? Technically, you can completely skip it when applying a test to the whole model. But doing so can actually reduce flexibility, so pay attention.
Due to flexibility issues, it is generally recommended to use external packages for making tests truly generic. Here is the same implementation using the dbt_utils package:
models:
- name: orders
tests:
- dbt_utils.unique_combination_of_columns:
combination_of_columns:
- order_id
- user_idTip 5: Try “dbt build” instead of “dbt run”

One last tip for today is not specifically about tests, but rather about the process of testing and building models.
In some cases, I have seen people running dbt projects as a chain of two or more commands, like this:
dbt run
dbt testWhat I don’t like in this approach is that quality issues in earlier models can migrate to final models.
For example, consider the case where staging model has some data quality issues, and descendant model inherits all those issues. We will know about problems with final model only after it is built and we run “test” command.

A better way to run this code might be dbt build command:

The build command sequentially builds and immediately tests models one by one. If parent model fails the test, further dependent models will not be built, which means that bugs in earlier models will not affect the final models.
This of course leads to slightly outdated final models, but al least you won’t get questions from stakeholders about incorrect data on dashboards. Additionally, if this approach is combined with alerting (e.g. a message in Slack), you will be the first to know about any problems with the data.
Also, if severity level of a failed test is “warning”, the pipeline won’t be stopped and dbt will proceed to building further models. This might be convenient is some cases.
That’s all for today!
Hopefully you learned a thing or two about using standard built-in dbt tests and will apply some of them in your project.
If you liked this issue please subscribe and share it with your colleagues, this greatly helps me developing this newsletter!
See you next time 👋