
Get The Ultimate Developer Experience for dbt
Few tricks to make your developer experience much better


“A good tool improves the way you work. A great tool improves the way you think.” Jeff Duntemann
The developers of dbt made a significant effort by incorporating software development practices into the world of data modeling. This includes version control, tests, documentation, and more. As a result, the lives of data analysts and data engineers have become much easier.
However, there are many more tools and practices that can improve the developer experience. As engineers, we want to work efficiently and focus more on business needs rather than code formatting or fixing errors in YAML files.
Today, I will show you how to improve your workflow with dbt. We will start slowly by optimizing your productivity in IDE by using “dbt Power User” plugin for VSCode. After that, I will demonstrate how to do SQL linting. And finally, will show you how to implement automatic checks of different parts of the project that will greatly enhance your developer experience.
Let's get started!
Supercharge your IDE

When developing in dbt, you typically work with a code editor (for SQL and Jinja) and a terminal (especially if you are a dbt Core user). One issue that dbt developers often face is the lack of good support for SQL + Jinja syntax in IDEs. So, let's fix that first.
I am a big fan of the VSCode. It provides excellent support for all major languages, such as Python, and offers a pleasant working experience. Additionally, it can be greatly enhanced by using plugins. Fortunately for us, there is a plugin specifically designed for dbt called "dbt Power User".
Installing the plugin is easy — basically you need to find it on the marketplace and install. Additionally, install official Python plugin, because dbt Power User depends on it. For most setups it should be sufficient. Now let’s see what is possible with it.
First of all, you are getting a contextual menu that can tell you a lot about the model: its parents and children, available tests and documentation and even a model lineage!
Additionally, you get a lot of additional perks like:
contextual suggestions of model names:

automatic generation of staging tables based on the source configuration
data preview
compile a single model using a key shortcut
and many more!

This plugin is a valuable asset for all dbt developers. Master it and increase your productivity by x100 times!
Lint and format SQL

Linting and formatting of SQL is very important when you work in a team. Without actively aligning and enforcing conventions, your project can quickly become disorganized, which can negatively impact readability and overall developer experience.
To address this, I recommend using a tool called SQLFluff. This open-source tool can be used to lint and format your SQL code. It provides numerous stylistic rules and coding conventions that will help maintain a high standard for your code base.
Installing SQLFluff into your project requires several steps:
Install the tool itself along with an additional plugin for dbt:
pip install sqlfluff sqlfluff-templater-dbtAdd .sqlfluffignore file to exclude some folders from checking:
analysis/ macros/ dbt_packages/ target/Add .sqlfluff file to configure SQL rules. Start simple, add more with time:
[sqlfluff] templater = dbt max_line_length = 80 dialect = snowflake [sqlfluff:templater:dbt] apply_dbt_builtins = true profile = my_dbt_profile project_dir = ./my_dbt_project profiles_dir = ~/.dbt [sqlfluff:indentation] indent_unit = space indented_ctes = False indented_joins = True indented_using_on = True indented_on_contents = True tab_space_size = 4 template_blocks_indent = True [sqlfluff:layout:type:comma] spacing_before = touch line_position = trailing [sqlfluff:templater:jinja] apply_dbt_builtins = true
Now you can use SQLFluff in the terminal. To lint all models from the "marts/" folder, simply run the following command:
$ sqlfluff lint models/marts
sqlfluff lint my_dbt_project/models/marts/
=== [dbt templater] Sorting Nodes...
=== [dbt templater] Compiling dbt project...
=== [dbt templater] Project Compiled.
== [my_dbt_project/models/marts/core/fact_orders.sql] FAIL
L: 26 | P: 40 | AL01 | Implicit/explicit aliasing of table.
| [aliasing.table]
L: 27 | P: 1 | LT02 | Expected indent of 4 spaces.
| [layout.indent]
L: 27 | P: 48 | AL01 | Implicit/explicit aliasing of table.
| [aliasing.table]
L: 28 | P: 1 | LT02 | Expected indent of 8 spaces.
| [layout.indent]
L: 29 | P: 1 | LT02 | Expected indent of 4 spaces.
| [layout.indent]
L: 29 | P: 30 | AL01 | Implicit/explicit aliasing of table.
| [aliasing.table]
L: 29 | P: 31 | LT01 | Unnecessary trailing whitespace.
| [layout.spacing]
L: 30 | P: 1 | LT02 | Expected indent of 8 spaces.
| [layout.indent]You will see the output from the linter, which shows the rules that your SQL code violates. From here, you can decide whether to fix the errors or adjust the rules.
SQLFluff can also automatically reformat the code to comply with the rules:
sqlfluff fix models/marts/core/fact_user_orders.sqlAnd that's basically it. Now you have a functional linting and formatting tool to help you maintain clean and consistent SQL code!
Automated checks on each commit
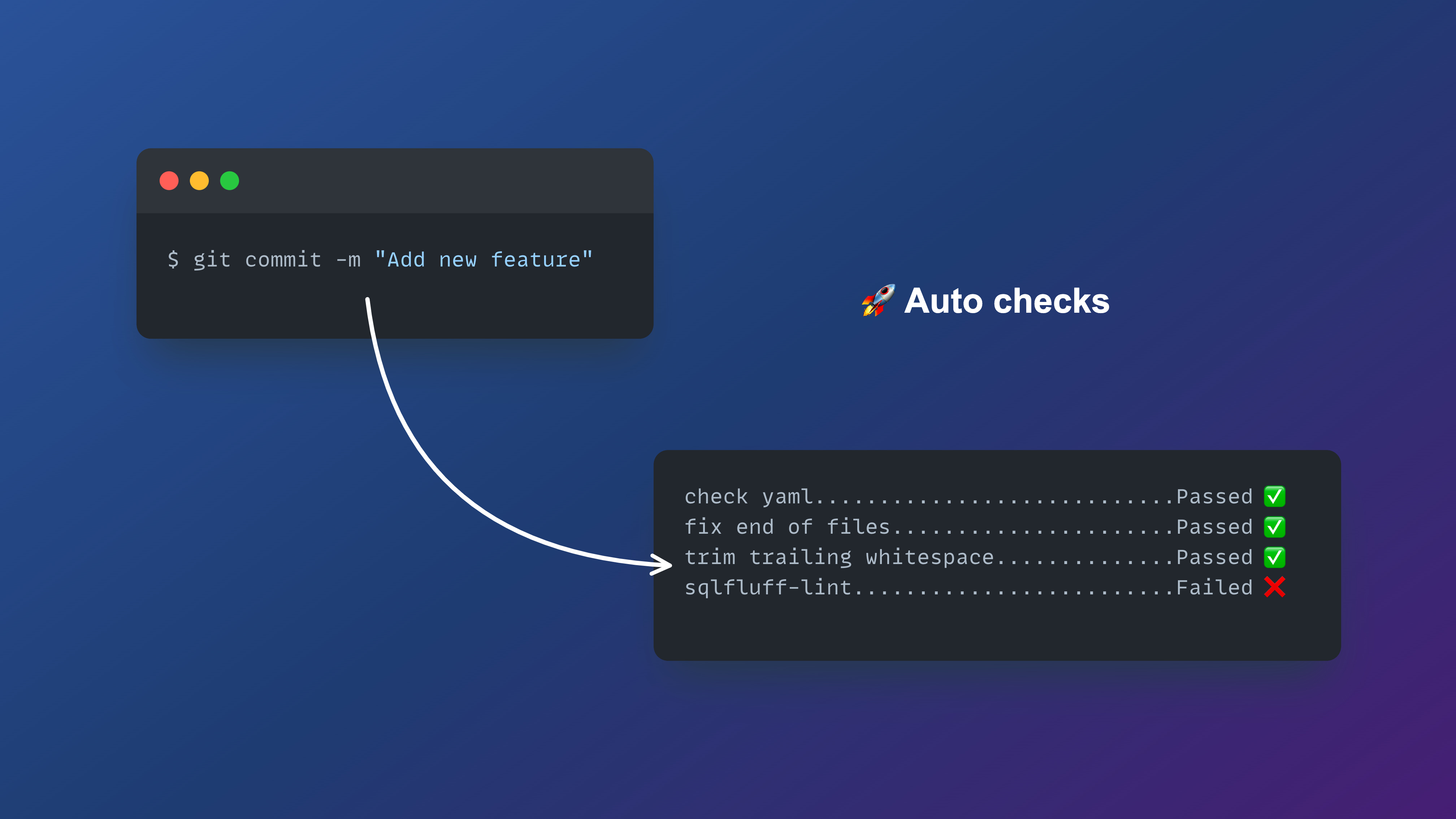
Finally, let's discuss more advanced topic of automation — pre-commit hooks. These are small scripts that can automatically run whenever you commit your code to the Git repository. Within these scripts, we can perform various checks to identify potential issues with the project and notify you of any problems. These checks are necessary to prevent you from committing faulty code that can cause issues.
In general, pre-commit hooks can work with any type of code, such as Python, NodeJS, PHP, etc., thanks to their extensions. Fortunately, there is also an extension available for working with dbt.
What can these hooks do? They can actually check a lot of stuff, including:
Validity of YAML files (e.g., sources and schema documentation)
General formatting of files (e.g., add missing end-of-line, or replacing double quotes with single quotes)
Check SQL code using SQLFluff
Presence of documentation for all models
Accuracy of documentation itself (e.g., ensuring all columns from a model are documented)
Availability of tests
and many more
To install pre-commit hooks you need to install the Python package itself and then add needed checks:
Install the package:
pip install pre-commitCreate .pre-commit-config.yaml file and place hooks:
repos: - repo: <https://github.com/pre-commit/pre-commit-hooks> rev: v4.4.0 hooks: - id: check-yaml - id: end-of-file-fixer - id: trailing-whitespace - repo: <https://github.com/sqlfluff/sqlfluff> rev: 2.1.2 hooks: - id: sqlfluff-lint additional_dependencies: [ 'dbt-snowflake', 'sqlfluff-templater-dbt' ] - repo: <https://github.com/dbt-checkpoint/dbt-checkpoint> rev: v1.1.1 hooks: - id: dbt-compile - id: dbt-docs-generate - id: check-source-table-has-description - id: check-model-has-tests args: ["--test-cnt", "1", "--"] - id: check-script-semicolon - id: check-script-has-no-table-name - id: check-model-has-all-columns
Next you may run all checks manually by running a command:
pre-commit run --all-filesOr by installing those hooks as preliminary step for “git commit” command with:
pre-commit installThe latter will write pre-commit configuration to the .git/hooks folder. From now on, whenever you make any commits, the pre-commit checks will be executed first.
That’s it for today!
If you liked this issue please subscribe and share it with your colleagues, this greatly helps me developing this newsletter!
See you next time 👋