
dbt basics refresher
Sometimes, it can be useful to go back to where it started


When working with some technology long enough you take a lot of things as granted. But it's always a good idea to refresh your knowledge and revisit the basics. This helps to ensure that you have a solid understanding of the fundamentals and can build on them effectively.
Furthermore, I believe that revisiting the basics also helps you acquire new knowledge. For instance, you may understand how certain components or processes function, but it is likely that you only utilize them in situations where you feel confident. However, the reality is that sometimes applying "basic" concepts can be much wiser.
So, let’s take some time to review the core concepts of dbt to enhance your skills and stay up to date with the latest advancements in the field.
What is dbt?
dbt is an open-source tool which ultimate goal is to help you build modular, reusable, and high-quality data models that can help your business answer its analytics questions.
I believe the latter is very important. If you provide value to the business, you are already using dbt correctly. Everything else is just optimizing the tool's usage.
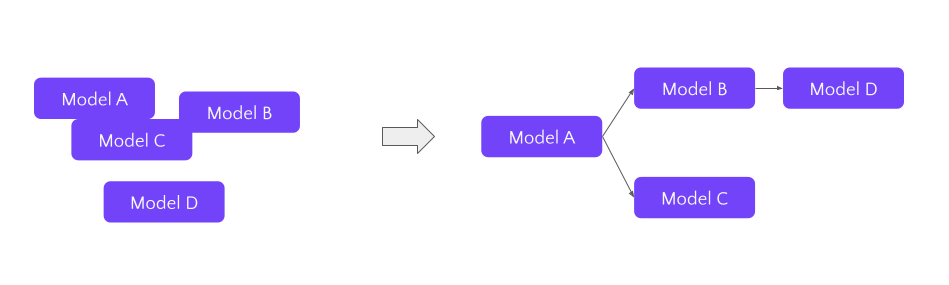
From the other perspective, dbt started in 2016 as a way to bring software engineering practices into data analytics. Most straightforward purpose of dbt is to organize your data models into understandable pipeline. So instead of a big pile of unconnected SQL scripts you get a DAG (direct acyclic graph). On top of that, you get all the practices of software engineering, like tests, version control, core review, CI/CD, etc.
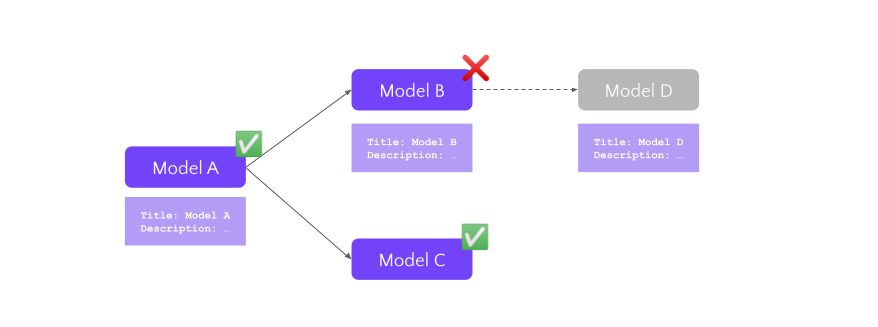
How dbt works, exactly?
To understand how dbt works internally you really need to understand it’s 4 topics:
Jinja templating
CLI commands
Sources and seeds
Compiled models
Let’s refresh all of them today.
Jinja templating
Jinja is the magic behind dbt.
It allows us to write dynamic SQL. Now we can do things that are normally not possible in SQL, for example:
conditional if statements
for loops
variables (to avoid hard-code)
reusable macros
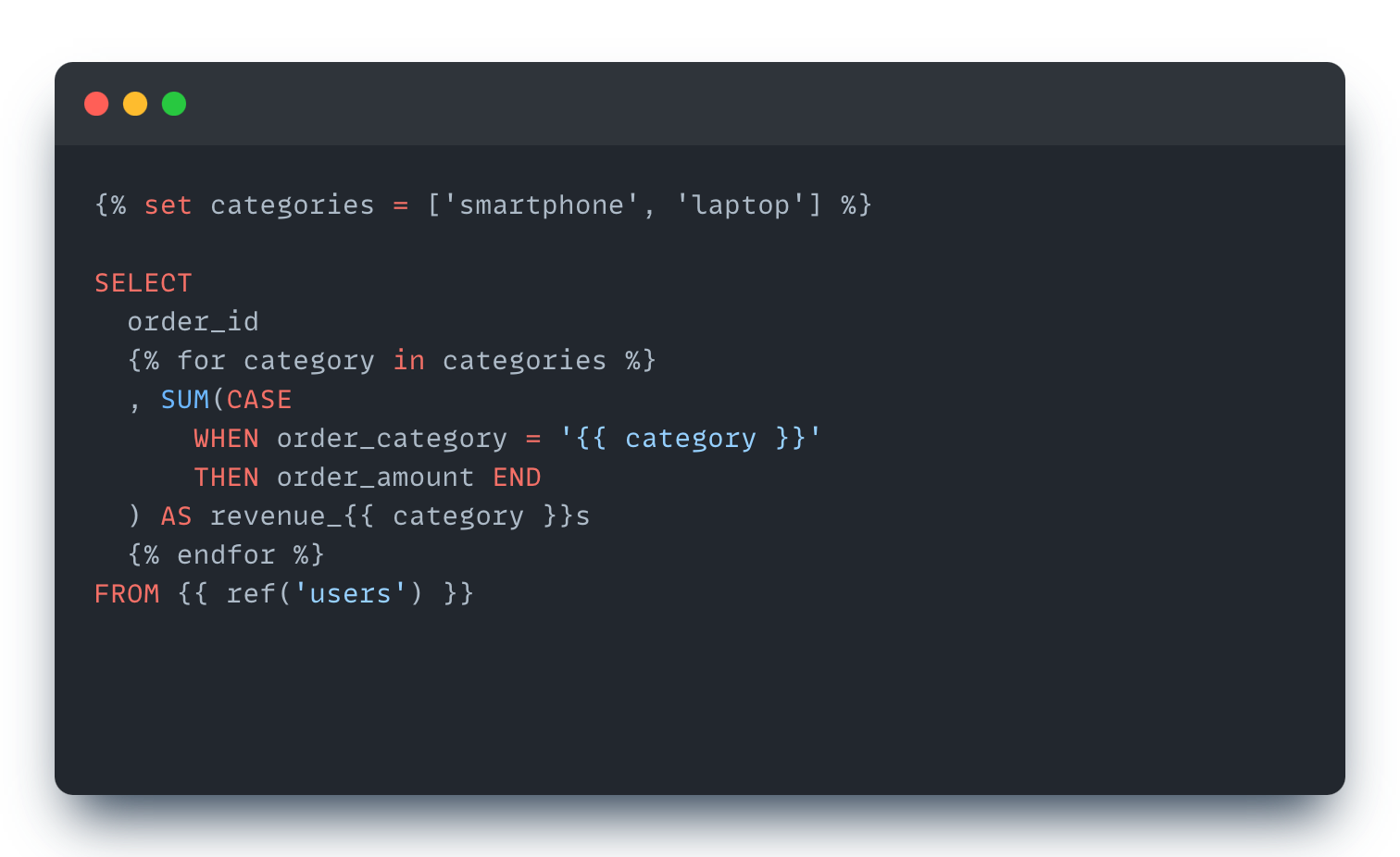
Worth mention, that Jinja is not invented by dbt, it’s a templating engine by its own. It is used in some Python web frameworks, like Flask or Django.
Jinja also has a concise syntax. There are three main templates that you will need to use:
Expressions
{{..}}are used to output a values, usually a string. You can output a variable or a result of macro.Statements
{%..%}are used for control flows, e.g. to set up “for” loops or “if” statements.Comments
{#..#}are Jinja comments and they won’t be compiled and rendered.
⚠️ One common mistake I see often is commenting out Jinja code with SQL comments. Such code will still be compiled!
Data warehouses do not understand Jinja. Therefore, Jinja code needs to be compiled before executing it in the database. I will discuss the compiling process in the last section, but I wanted to clarify this here to avoid any confusion about running Jinja code in the database.
One of the most useful Jinja code in dbt is ref() macro. It helps dbt understand dependencies between models and allows to avoiding table name hardcoding (because ref() macro will be translated to the real name of table/relation during compilation).
Finally, here are a few interesting pieces about ref macro:
It is possible to do referencing “without” ref in FROM, by specifying a special SQL comment.
ref() macro actually can take two arguments for more explicit referencing (first argument is a project name, useful for external packages and better visibility).
Since dbt models can have versions, you can add model version along with its reference name.
Here is an awesome Jinja guide from dbt team itself.
CLI commands
dbt was initially invented as CLI tool. And for vast majority of features it still is a CLI tool. That’s why it is vital to know how to use dbt in the command line.
Here is a shortlist of my most used dbt commands:
dbt debug — used to check dbt project health and database connection
dbt run — runs the models in a project, probably most used command in any project
dbt compile — helps you compile models in the project, could be useful for debugging purposes
dbt build — a command to build and test all dbt resources (models, seeds, snapshots, tests). can be very handy when running in Production
All commands above are going to run all models in your project. It may be not needed in all cases, for example during development stage. So all commands support selection syntax which allows you to run only a subset of models.
Selection is implemented with --select argument that limits commands only to the specific models:
dbt run --select model_a
# this is the same as above, but shortened
dbt run -s my_model
# run several models
dbt run -s model_a model_b
Sometimes you may want to run a model along with all its dependencies, or a model and its parents, etc. To achieve that you could use selector modifiers:
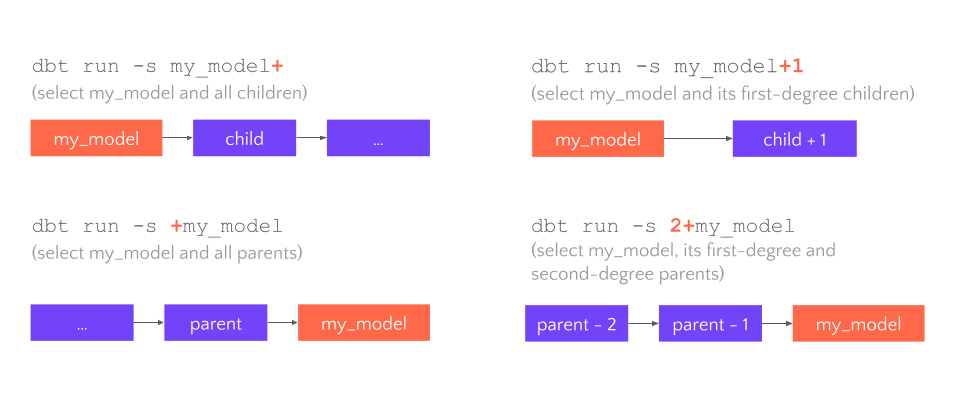
Sources and seeds
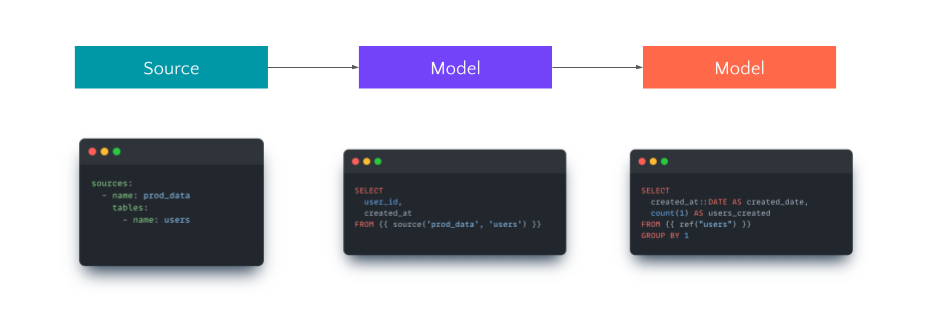
Sources are used to describe the data that already exists in your data warehouse. In dbt, you will use sources to build your models.
Sources are described in .yaml files. You can define multiple sources and multiple tables inside one source:
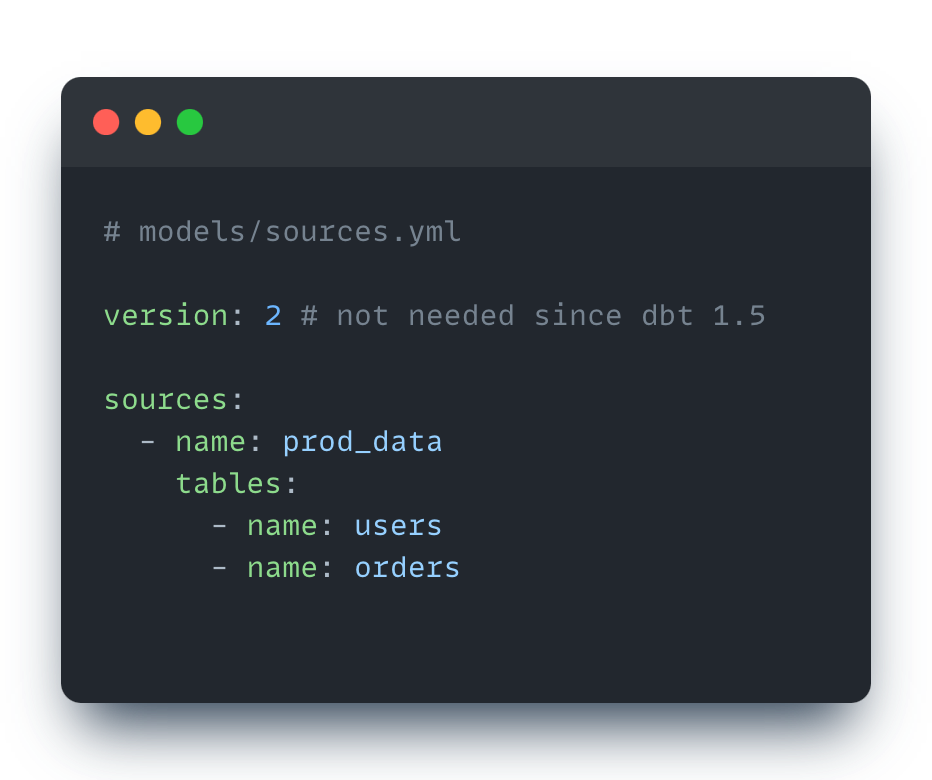
To use source in the model, use the following macro:
{{ source('source', 'table') }}In the final dbt pipeline, when you want to use data source you use source() macro, when you want to use another dbt model you use ref() macro.
Each data source can be checked for freshness. You can set acceptable timeframe of data availability to consider a source “fresh”.
Freshness can be set either for the whole source set of for each table separately. To trigger freshness check you need to use the following command:
dbt freshnessSeveral advanced cases of advanced usage of dbt sources:
Freshness is not checked during dbt build. If you need that, create additional step.
It’s possible to define EXTERNAL TABLE as dbt source, however you still need to use dbt-external-tables package to update the definition in DWH.
Data source from external package can be overwritten with overrides property.
Sometimes source data can be defined in a static file, for example CSV file with some mappings. These are called seeds in dbt.
Seeds are used to load static data into your data warehouse. Seeds are .csv files located in /seeds folder within your dbt project. Seeds are useful when you have a data that doesn't change frequently, such as dictionaries, lookup tables, or other types of static data.
For better compatibility with DWH it is recommended to create .yml file with data types and definitions.
Compiled models
Finally, let's discuss the compilation of dbt models. As mentioned earlier, our databases cannot read Jinja code directly from our models. Therefore, before running models in the database, dbt will translate Jinja code into plain SQL code and then execute it.
Compilation is done automatically whenever you use dbt run command or can be done via a special command dbt compile.
All compiled code it stored in /target folder. Its content usually not committed to Git repository, because it can be easily recreated by run or compile commands.
There will be two subfolders in target:
/compiled is a folder with dbt models, directly compiled to SQL. This code, however, will not be executed in the database directly, because these are only SELECT statements.
/run is a folder of compiled dbt models with additional DDL (data definition language) code. These scripts will be executed in the database. DDL is a code that handles the creation of tables and views, as well as the insertion of new rows for incremental models. It essentially takes care of the heavy lifting that is typically done by data engineers.
You can use node selection syntax with compile command
dbt compile --select users_modelAlso, you can compile an inline code, like this:
dbt compile --inline "select * from {{ ref('orders') }}"Both options of running are interactive, meaning the result will be printed to the terminal.
⚠️ Compilation requires a working connection to the DWH! Read FAQ about that in the documentation.
I hope this refresher post was useful and you learned a thing or two about basic concepts of dbt. Take your time to to review these fundamentals and create a strong foundation to build upon.
If you liked this issue please subscribe and share it with your colleagues, this greatly helps me developing this newsletter!
See you next time 👋