

Native unit-testing in dbt
Native unit-testing in dbt
A primer on how to implement unit tests in dbt


The release of dbt v1.8 will introduce native unit-testing capabilities. This exciting new feature, long-awaited by many, is significant for several reasons. In this post I’ll explore why this feature is important, how it differs from existing dbt tests, and how you can apply it to your existing project.
What is unit testing?
In software engineering, unit testing is a process in which you test the smallest parts of your code. Typically, these are functional units such as functions or methods within a class. This involves providing some input values and observing the output to figuring out if the code works as expected. For any given input, there should be an expected output - this is the essence of unit testing.
Applying this concept to dbt, the smallest functional unit would be a model. Similar to functions, a model takes one or more inputs (other models) and produces an output (the resulting dataset).
In accordance with unit testing principles, you could simulate an input and expect an output for any given dbt model.
This approach differs from the classic dbt tests approach for two reasons:
Existing dbt tests are too generic and lack knowledge of the underlying logic.
It's necessary to build the model before testing it.
Testing logic 🤔
In SQL, you might encounter numerous logical transformations, such as applying column functions, window functions, complex CASE statements, and string manipulations. Such logic is challenging to test with generic tests due to the lack of context for the transformation. However, in unit testing, you know the input, allowing you to anticipate a specific output. This makes testing such logic more viable.
Think about how often you had to modify the logic of a model because a real test case revealed that the existing logic was flawed. Reported bugs and edge cases serve as excellent input sources for unit testing. By using these, you can strengthen your models against future changes and prevent the repetition of past errors.
Unit testing is especially useful during refactoring. When refactoring affects a large number of models, it's challenging to ensure that the existing logic remains intact and no new bugs are introduced. If you have unit tests in place, you can confidently maintain the expected functionality without breaking production models.
Testing without building 👷
Another great benefit of unit testing is a testing using mock data and without building models with production data.
Using mock data in unit testing can provide faster results, as it eliminates the need to process your entire dataset. This approach allows you accelerate development cycle and simplify troubleshooting, as you don't have to wait for large amounts of data to be processed and transformed. This not only saves time but also resources, making your data warehouse bill much lower.
Finally, mock data provides a better understanding of what the output results should look like. This is because you can model the expected behavior even in an Excel spreadsheet.
Unit testing in dbt 1.8
⚠️ By the time of writing this article, unit testing is still in beta. Yet, you still could try this functionality to test-drive it. In the “Demo” section I’ll show you how to do that.
To implement unit testing in dbt, you need to take a few steps. Firstly, configure the unit test itself. Secondly, create mock data, which will serve as the input for your models and additionally the expected output. To simplify this process, the developers of dbt have combined these steps.
To define a unit test in dbt, create a config file in YAML format. This is similar to how you would document your models or define data sources. Within the /models folder, create a file named unit_testing.yaml (the name is arbitrary, you can use something else).
Inside of the file let’s define our unit test:
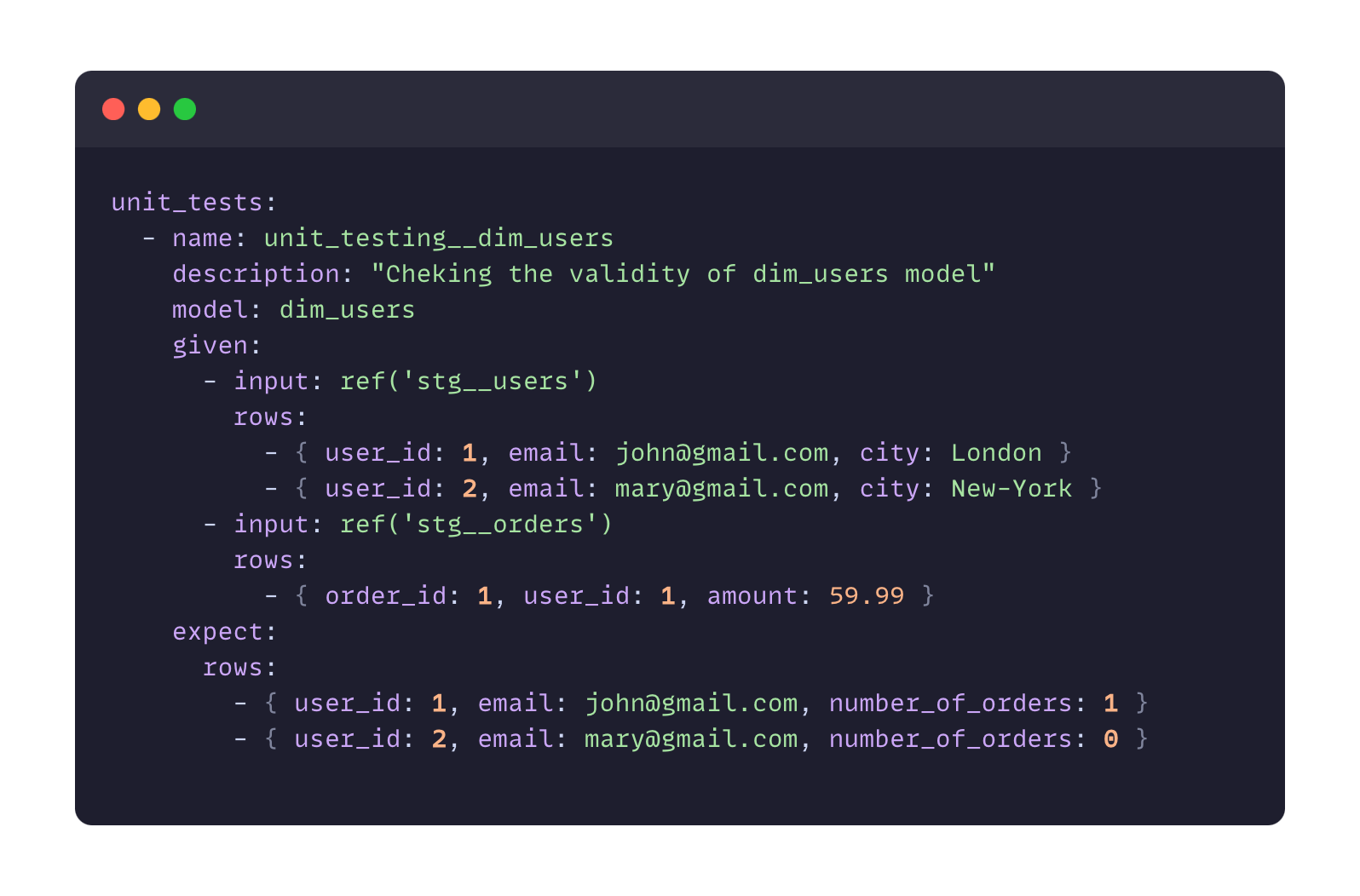
You need to define a few components here:
The name and description of the unit test
The referencing model
The input (mock) data inside the “given” parameter
The expected output in the “expect” parameter
In the example above, mock data is defined as JSON rows, but it also can be defined as CSV rows like this:
- input: ref('stg__users')
format: csv
rows: |
user_id,email
1,john@gmail.com
2,mary@gmail.comYou have several options to run the test(s):
# run all tests on dim_users model, including unit tests:
dbt test -s dim_users
# run only unit tests:
dbt test -s "dim_users,test_type:unit"
# run a test by its name:
dbt test -s unit_testing__dim_usersRemember, if the model you're testing relies on another model (which is likely in 99% of cases), you need to materialize the parent model first. However, there's a workaround to bypass full materialization step. You can create empty tables for upstream models like this:
dbt run -s "stg__users stg__orders" --emptyDemo
To demonstrate how unit testing works in real life I’ve prepared a simplest demo example. Similarly to the example above, it shows a pipeline of building dim_users model out of users and orders tables:

You can find the project in this repo. You can try it in Github Codespaces, see the instructions in the README.
Next, in file _unit_tests.yml you can find a configuration of the test. It’s pretty much the same as in the example above.
To run the test, you can try dbt test:
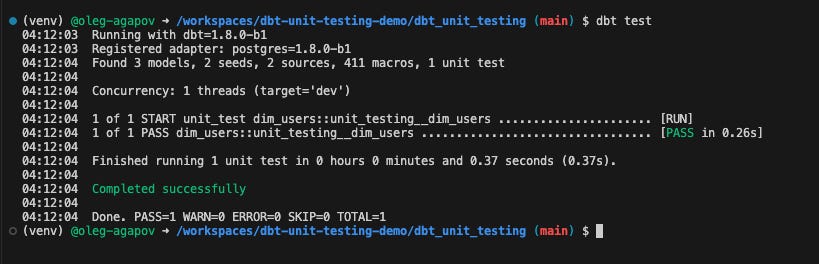
As you can see, the test was successful since the output matched the expected result. To simulate a failed test, you could modify the dim_users model. For example, change the LEFT JOIN to an INNER JOIN. After re-running the test, you're likely to notice a difference:
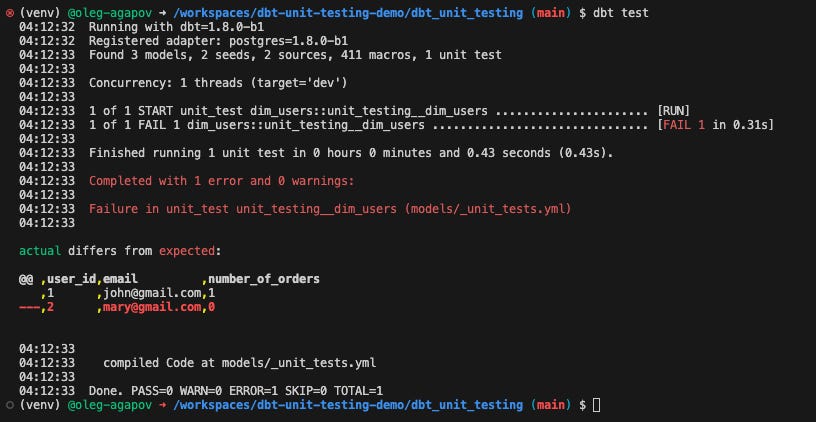
The output indicates that the actual result does not match the expected one, and it even highlights the problematic rows. This is unit testing in action!
If you liked this issue please subscribe and share it with your colleagues, this greatly helps me developing this newsletter!
See you next time 👋
Thanks for this post. I'm wondering if it would be possible to create a separate data file (csv / jsonl[1]) to provide the data? Because while the sandbox example is great, on real-world prod usually we have like 20-30+ fields (columns) models and describe the data in yaml file using the following
```
- input: ref('stg__users')
format: csv
rows: |
```
causes eye pain. So I'm wondering if it would be possible to create something like `dbt-project/unit_testing/stg__users/input.csv` where we could comfortably describe the data and then link this file to the test configuration.
Thanks in advance!
[1]. https://jsonlines.org/